例子一:
保存通过URL(https://movie.douban.com)获取到的网页源代码和内容:
笺注:
当前很多网站都有反爬虫机制,对于爬虫请求会一律拒绝。
网站的程序是怎样区分一个请求是正常请求还是爬虫程序发出的请求呢?
网站的程序其实是通过判断发送请求中是否有浏览器信息,从而区分一个请求是正常请求还是爬虫程序发出的请求。
当访问有反爬虫机制的网站时,可以在请求中设置浏览器信息(伪装成浏览器),这是通过修改http包中的headers实现。
脚本内容:
#coding=utf-8
import urllib.request #内置模块,无需额外安装
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201Firefox/3.5.6′
}
url_1 = ‘https://movie.douban.com’ #网站 (豆瓣电影)的URL
ret = urllib.request.Request(url_1,headers = headers)
response = urllib.request.urlopen(ret)
Key_1 = response.read().decode(“utf-8”)
Path_1 = “./1.txt”
f_name = open(Path_1,’w’,encoding=’utf-8′) #写入(覆盖)文件内容
Result_1 = f_name.write(Key_1)
f_name.close()
运行脚本的结果:(脚本所在目录下会生成文件1.txt,文件里会包含网页源代码和内容)
C:\Users\jacky\Desktop>python xx.py
C:\Users\jacky\Desktop>
######
例子二:
从例子一获取的数据中筛选出版块[正在热映]下的所有电影名称:
笺注:
版块[正在热映]的电影名称格式,如下:
<li class=”ui-slide-item” data-title=”边缘行者” data-release=”2022″ data-rate=”5.3″ data-star=”30″ data-trailer=”https://movie.douban.com/subject/35192672/trailer” data-ticket=”https://movie.douban.com/ticket/redirect/?movie_id=35192672″ data-duration=”113分钟” data-region=”中国大陆” data-director=”黄明升” data-actors=”任贤齐 / 任达华 / 方中信” data-intro=”” data-enough=”true” data-rater=”12771″>
<li class=”ui-slide-item” data-title=”少年英雄董存瑞” data-release=”2022″ data-rate=”” data-star=”00″ data-trailer=”https://movie.douban.com/subject/35917114/trailer” data-ticket=”https://movie.douban.com/ticket/redirect/?movie_id=35917114″ data-duration=”82分钟” data-region=”中国大陆” data-director=”张利鹏” data-actors=”林子杰 / 高宇阳 / 赵中华” data-intro=”” data-enough=”false” data-rater=”4″>
<li class=”ui-slide-item” data-title=”小妈妈 Petite maman” data-release=”2021″ data-rate=”7.9″ data-star=”40″ data-trailer=”https://movie.douban.com/subject/35225859/trailer” data-ticket=”https://movie.douban.com/ticket/redirect/?movie_id=35225859″ data-duration=”72分钟” data-region=”法国” data-director=”瑟琳·席安玛” data-actors=”约瑟芬·桑兹 / 加布里埃尔·桑兹 / 尼娜·梅尔瑞斯” data-intro=”” data-enough=”true” data-rater=”11007″>
脚本内容:
#coding=utf-8
import re #导入正则表达式的模块;内置模块,无需额外安装
from io import StringIO
String_1 = StringIO()
def func1(): #读取文件内容
Path_1 = “./1.txt”
f_name = open(Path_1,’r’,encoding=’utf-8′)
fields_1 = f_name.readlines() #输出结果为列表,包含换行符
f_name.close()
func2(fields_1)
def func2(fields_1): #从func1()获得的数据中进行筛选
print(‘版块[正在热映]下的所有电影名称:’)
K_1 = ‘data-title=’ #关键字
for Key_1 in fields_1:
if K_1 in Key_1:
Result_1 = re.compile(u'<li.*?data-title=”(.*?)”.*?’)
Result_2 = Result_1.findall(Key_1)
print(Result_2[0])
Result_3 = f”{Result_2[0]}\n”
String_1.write(Result_3)
Result_4 = String_1.getvalue()
func3(Result_4)
def func3(Result_4): #把电影名称保存到文件
Path_1 = “./2.txt”
f_name = open(Path_1,’w’,encoding=’utf-8′) #写入(覆盖)文件内容
Result_1 = f_name.write(Result_4)
f_name.close()
if __name__ == ‘__main__’:
func1()
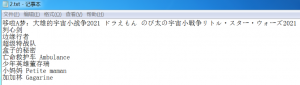
脚本运行的结果:
C:\Users\jacky\Desktop>python xx.py
版块[正在热映]下的所有电影名称:
哆啦A梦:大雄的宇宙小战争2021 ドラえもん のび太の宇宙小戦争リトル・スター・ウォーズ2021
刿心剑
边缘行者
超级特战队
盒子的秘密
亡命救护车 Ambulance
少年英雄董存瑞
小妈妈 Petite maman
加加林 Gagarine
C:\Users\jacky\Desktop>
脚本所在目录下会生成文件2.txt,文件里会包含版块[正在热映]下的所有电影名称: